Flickr30K Entities to rozszerzenie popularnego zestawu Flickr30K, który zawiera ponad 31 000 obrazów z platformy Flickr. Każdy obraz posiada pięć opisów na podstawie crowd-source, a nowa wersja dodaje 244 000 łańcuchów koreferencyjnych oraz oznaczenia ramkowe dla obiektów obecnych na zdjęciach.
Zastosowania: Generowanie opisów obrazów w czasie rzeczywistym, wyszukiwanie obrazów.
Licencja: Użytkowanie zgodne z zasadami platformy Flickr do celów badawczych i edukacyjnych.
2. InternVid
InternVid to nowoczesny zestaw danych przeznaczony do analizy wideo, zawierający ponad 7 milionów wideo o łącznym czasie trwania około 760 000 godzin. Klipy wideo, których jest aż 234 miliony, są powiązane z bogatymi opisami, składającymi się w sumie z ponad 4,1 miliarda słów.
Zastosowania: Tworzenie chatbotów wideo, personalizowana edukacja online.
Licencja: Licencja Apache 2.0.
3. MuSe-CaR (Multimodal Sentiment Analysis in Car Reviews)
Zestaw MuSe-CaR skupia się na analizie emocji w kontekście recenzji wideo, dostarczając ponad 40 godzin materiału wideo z bogatymi adnotacjami. Dane te pokazują elementy emocjonalne, takie jak mimika, gesty czy intonacja głosu.
Zastosowania: Chatboty do diagnozy zdrowia psychicznego, automatyczny system analizy zadowolenia klientów.
Licencja: Do użytku niekomercyjnego zgodnie z licencją EULA.
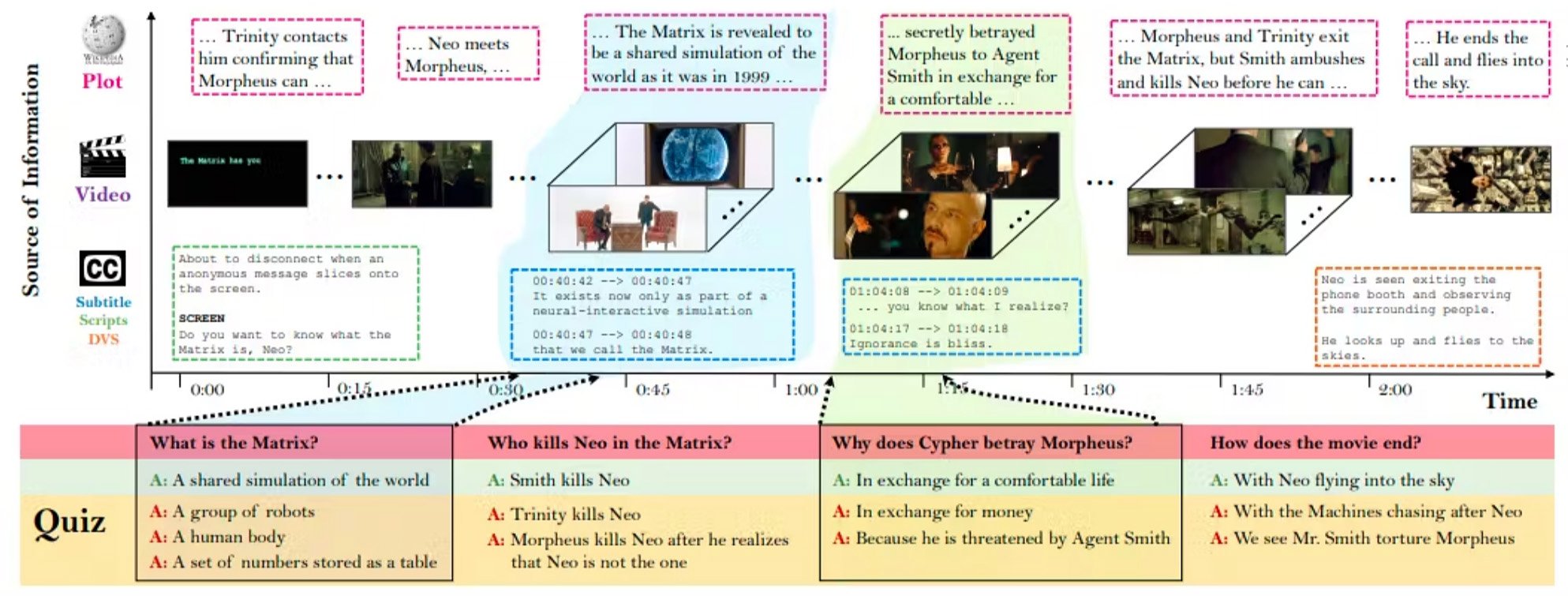
4. MovieQA
MovieQA to multimodalny zestaw pytań i odpowiedzi związany z fabułą filmów. Obejmuje ponad 15 000 pytań wielokrotnego wyboru związanych z fragmentami filmów, wokół których zawarto narrację, napisy i opisy.
Zastosowania: Automatyczna analiza filmów, tworzenie streszczeń.
Licencja: Nieokreślona.
5. MINT-1T
Największy zestaw danych w tej kategorii, MINT-1T, zawiera aż bilion tokenów tekstowych i 3,4 miliarda obrazów. Został zaprojektowany, aby odzwierciedlać rzeczywiste dokumenty, takie jak strony internetowe czy naukowe publikacje, z wykorzystaniem sposobu łączenia tekstu i obrazów.
Zastosowania: Tworzenie bardziej kontekstualnych asystentów AI.
Licencja: Licencja Creative Commons BY 4.0.

{kind=link}