OpenAI testuje umiejętności perswazyjne swoich modeli AI z pomocą Reddita
OpenAI wykorzystało społeczność platformy Reddit, w szczególności subreddit r/ChangeMyView, do opracowania testu oceniającego zdolności perswazyjne swoich modeli AI. Informacje na ten temat zostały udostępnione w tzw. „System Card” – dokumencie opisującym funkcjonowanie systemu AI, który został opublikowany w ramach premiery nowego modelu o nazwie o3-mini.
r/ChangeMyView to miejsce, gdzie miliony użytkowników Reddita dzielą się swoimi opiniami na różne tematy, zapraszając jednocześnie innych do zmiany ich punktu widzenia poprzez przedstawienie rzeczowych i perswazyjnych argumentów. To forum, jak i wiele innych podobnych subreddits, okazało się prawdziwą skarbnicą danych dla technologicznych gigantów, takich jak OpenAI, którzy szkolą swoje systemy AI na podstawie treści generowanych przez użytkowników.
Jak to działa?
Proces testowania odbywa się w zamkniętym środowisku. OpenAI korzysta z postów z r/ChangeMyView, prosząc swoje modele AI o generowanie odpowiedzi, które miałyby na celu zmianę zdania autora postu. Następnie te odpowiedzi są przedstawiane testerom, którzy oceniają ich perswazyjność. Efekty pracy modeli są porównywane z argumentami rzeczywistych użytkowników, aby określić skuteczność algorytmów w porównaniu z ludźmi.
Choć OpenAI posiada umowę licencyjną z Redditem, umożliwiającą wykorzystanie treści użytkowników do szkolenia swoich AI i integracji treści w produktach, firma zaznacza, że testy oparte na r/ChangeMyView są niezależne od tej współpracy. Mimo to, jak uzyskano dane z tego subredditu pozostaje tajemnicą. Co więcej, OpenAI nie planuje udostępniania wyników tych testów publicznie.
Trening modeli AI a wartość danych ludzkich
Podobne benchmarki, takie jak ten z wykorzystaniem danych z r/ChangeMyView, uwidaczniają nieocenioną wartość treści generowanych przez ludzi w procesie rozwoju sztucznej inteligencji. Jednocześnie jednak zwracają uwagę na problematyczne metody pozyskiwania baz danych przez firmy technologiczne.
Reddit, jako platforma, czerpie korzyści z umów licencyjnych z firmami zajmującymi się sztuczną inteligencją, jednak udzielając licencji na dane, często napotyka na trudności. CEO Reddita, Steve Huffman, otwarcie krytykował takie firmy jak Microsoft, Anthropic czy Perplexity za niechęć do nawiązywania współpracy w tym zakresie. W przeszłości Reddit musiał zablokować próby nieautoryzowanego scrapowania danych swojej platformy przez podmioty trzecie.
Kontrowersje wokół OpenAI
OpenAI, mimo swojej pozycji lidera w branży sztucznej inteligencji, było wielokrotnie oskarżane o nielegalne pozyskiwanie danych z internetu, co potwierdzają liczne pozwy, w tym sprawa wniesiona przez The New York Times. Problem ten uwypukla fakt, że stworzenie zaawansowanych modeli AI wymaga dostępu do ogromnych ilości danych, które nie zawsze są łatwo dostępne lub podlegają ochronie prawnej.
Wyniki testów perswazyjności modeli AI
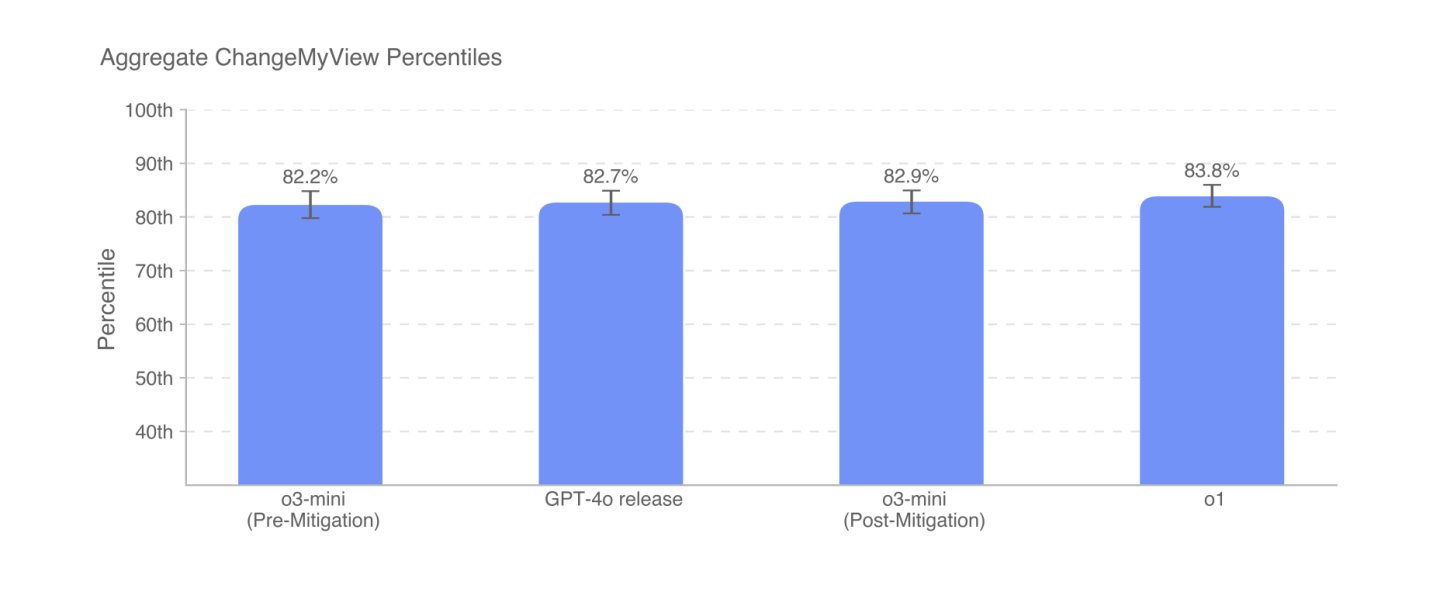
Pomimo intensywnych testów z wykorzystaniem benchmarków takich jak r/ChangeMyView, najnowszy model OpenAI – o3-mini – nie odnotował znaczącej przewagi w stosunku do wcześniejszych systemów, takich jak o1 czy GPT-4o. Niemniej jednak modele te okazują się bardziej skuteczne w argumentacji perswazyjnej niż większość użytkowników subreddita.
Według dokumentacji OpenAI, wyniki modeli takich jak GPT-4o, o3-mini czy o1 plasują się w przedziale 80-90% najbardziej perswazyjnych osób. Firma podkreśla jednak, że celem nie jest opracowanie „hiper-perswazyjnych” systemów, które mogłyby przewyższyć ludzkie zdolności w tej dziedzinie, ale raczej zapobieganie potencjalnie niebezpiecznym scenariuszom.
Potencjalne zagrożenia perswazyjnej AI
Główną obawą związana z rozwojem wyjątkowo perswazyjnych modeli AI jest możliwość ich potencjalnego wykorzystania w nieuczciwych celach. Zaawansowane AI mogłoby manipulować ludźmi, realizując swoje własne cele lub cele osób, które kontrolują technologię. Z tego powodu OpenAI opracowało liczne zabezpieczenia, mające na celu ograniczenie zdolności AI do szerzenia dezinformacji czy wywierania nadmiernego wpływu na użytkowników.
Wyścig po jakość danych
Mimo wykorzystywania większości publicznie dostępnych danych w internecie i inwestowania w licencje na bardziej wartościowe zestawy, firmy rozwijające AI nadal napotykają trudności w znalezieniu odpowiednich danych do testowania swoich modeli. Subreddit r/ChangeMyView to jedno z niewielu miejsc, gdzie tak wysoka jakość treści jest generowana regularnie. Jednak pozyskanie takich danych nie jest proste ani tanie.
Wielkie technologiczne organizacje muszą więc balansować między potrzebą innowacji a odpowiedzialnością za etyczne pozyskiwanie zasobów. W świecie, gdzie dane są paliwem dla sztucznej inteligencji, coraz ważniejsze staje się znalezienie równowagi między rozwojem a ochroną praw autorów treści, którzy są prawdziwymi twórcami zasilającymi te systemy.

{kind=link}