Zespół badawczy Hao AI Lab z University of California San Diego otrzymał system NVIDIA DGX B200, aby przyspieszyć prace nad wnioskowaniem (inference) dla dużych modeli językowych (LLM). Urządzenie trafiło do zasobów dostępnych dla członków laboratorium oraz szerszej społeczności UC San Diego w School of Computing, Information and Data Sciences w ramach San Diego Supercomputer Center, otwierając nowe możliwości eksperymentów i prototypowania na wydajnym sprzęcie.
Hao AI Lab jest rozpoznawalny jako źródło kilku koncepcji, które trafiły do produkcyjnych platform do wnioskowania LLM, w tym do projektu NVIDIA Dynamo; jednym z kluczowych rozwiązań opracowanych w laboratorium jest DistServe. Dzięki dostępowi do DGX B200 badacze mogą szybciej testować pomysły i skalować eksperymenty, co, jak podkreśla Hao Zhang — adiunkt w Halıcıoğlu Data Science Institute oraz w Katedrze Informatyki i Inżynierii UC San Diego — pozwala na znacznie szybsze prototypowanie niż przy użyciu starszych generacji sprzętu.
Jak zespół wykorzystuje DGX B200
DGX B200 wspiera kilka projektów Hao AI Lab, w szczególności FastVideo oraz Lmgame-bench. FastVideo to linia modeli do generowania wideo, której celem jest stworzenie pięciosekundowego klipu na podstawie opisu tekstowego w czasie równym pięciu sekundom. Faza badawcza tego projektu wykorzystuje zarówno system DGX B200, jak i procesory graficzne NVIDIA H200.
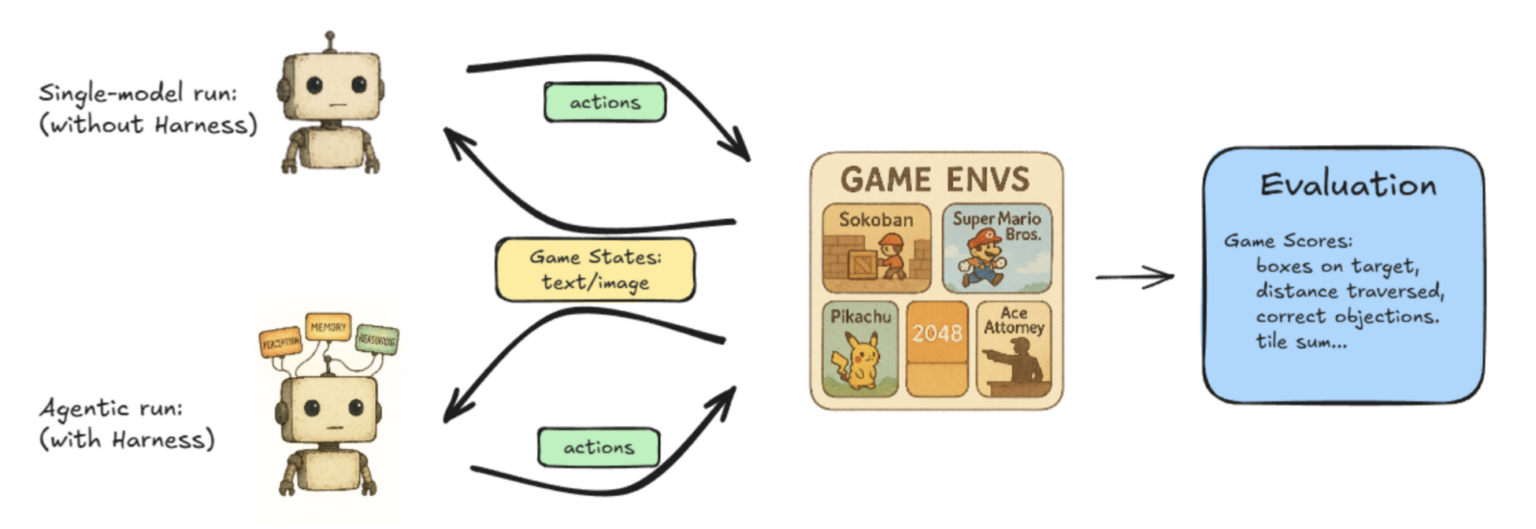
Lmgame-bench to zestaw benchmarków sprawdzający możliwości modeli językowych w kontekście popularnych gier online, takich jak Tetris i Super Mario Bros. Platforma pozwala oceniać pojedyncze modele lub konfrontować ze sobą dwie sieci, mierząc ich wydajność w zadaniach związanych z grami. Ponadto laboratorium prowadzi prace nad rozwiązaniami mającymi na celu obsługę LLM z bardzo niskimi opóźnieniami, dążąc do tego, by modele odpowiadały w czasie zbliżonym do rzeczywistego. Jak zauważa Junda Chen, doktorant informatyki na UC San Diego, DGX B200 umożliwia eksplorację „następnego etapu” obsługi LLM o niskich opóźnieniach dzięki swoim imponującym parametrom sprzętowym.
DistServe i podejście do „disaggregated serving”
Disaggregated inference to podejście, które pozwala dużym systemom do obsługi LLM optymalizować całkowitą przepustowość przy jednoczesnym zachowaniu akceptowalnych opóźnień dla użytkowników. Kluczową ideą opracowaną w ramach DistServe jest zmiana metryki z tradycyjnej „throughput” na „goodput”.
Throughput mierzy liczbę generowanych tokenów na sekundę przez cały system — wyższa wartość oznacza niższy koszt wytworzenia pojedynczego tokena. Jednak sama przepustowość nie przekłada się bezpośrednio na to, jak szybko odpowiedź otrzyma użytkownik; aby zmniejszyć opóźnienie postrzegane przez użytkownika, system często musi poświęcić część throughputu. DistServe proponuje więc metrykę goodput, definiowaną jako przepustowość realizowana przy jednoczesnym spełnieniu z góry określonych celów dotyczących opóźnień (service-level objectives). Goodput odzwierciedla zatem efektywność systemu w kontekście jakości obsługi i kosztów, pozwalając osiągnąć optymalną równowagę między wydajnością a doświadczeniem użytkownika.
Jak praktycznie osiągnąć lepszy goodput
W pipeline generowania odpowiedzi przez LLM rozróżnia się dwa etapy: prefill oraz decode. Prefill to generowanie pierwszego tokena na podstawie wejścia użytkownika, etap mocno obciążający obliczeniowo; decode to serię kolejnych tokenów przewidywanych na podstawie wcześniejszych wyników, etap bardziej intensywny pamięciowo. Tradycyjnie oba etapy były wykonywane na tej samej karcie GPU, co powodowało konkurencję o zasoby i pogorszenie opóźnień z perspektywy użytkownika. Badacze DistServe wykazali, że rozdzielenie prefill i decode na różne zestawy GPU — czyli tzw. prefill/decode disaggregation — redukuje wzajemną interferencję zadań, przyspiesza oba etapy i maksymalizuje goodput.
Takie rozdzielenie pozwala na skalowanie obciążenia bez poświęcania niskich opóźnień ani jakości generowanych odpowiedzi. Otwarta architektura Dynamo, zaprojektowana do skalowania modeli generatywnych przy wysokiej efektywności kosztowej, wspiera wdrażanie strategii disaggregated inference, co ułatwia przenoszenie koncepcji DistServe do praktyki produkcyjnej.
Równolegle z tymi technicznymi kierunkami badawczymi, na uczelni rozwijane są także międzywydziałowe projekty w obszarach takich jak opieka zdrowotna i biologia, które korzystają z mocy obliczeniowej DGX B200. Dzięki temu badacze sprawdzają, jak platformy AI mogą przyspieszać innowacje w interdyscyplinarnych zastosowaniach naukowych.

{kind=link}