Modele językowe o dużej skali (LLM) zmieniają sposób pracy użytkowników, rewolucjonizując produktywność i wprowadzając nowe możliwości w zakresie sztucznej inteligencji (AI). Modele te potrafią tworzyć dokumenty, podsumowywać strony internetowe oraz odpowiadać na pytania na różne tematy, opierając się na olbrzymich ilościach danych, na których zostały wytrenowane.
Szerokie zastosowanie modeli językowych
LLM stanowią fundament wielu rozwijających się aplikacji związanych z generatywną AI, takich jak asystenci cyfrowi, konwersacyjne awatary czy agenci obsługi klienta. Wiele nowoczesnych modeli można uruchamiać bezpośrednio na komputerach osobistych lub stacjach roboczych, co daje użytkownikom szereg korzyści, m.in. możliwość zachowania prywatności danych na urządzeniu, korzystanie z AI bez dostępu do internetu czy wykorzystanie mocy obliczeniowej układów GPU, takich jak NVIDIA GeForce RTX.
Jednakże, niektóre modele, ze względu na swoją wielkość i złożoność, nie mieszczą się w pamięci wideo lokalnego GPU (VRAM) i wymagają specjalistycznego sprzętu dostępnego w dużych centrach danych. Mimo to, istnieje rozwiązanie, które pozwala przyspieszyć działanie części takich modeli na lokalnych komputerach z GPU RTX, wykorzystując technikę zwaną GPU offloading. Dzięki niej użytkownicy mogą korzystać z akceleracji GPU bez konieczności ograniczania się do pojemności VRAM dostępnej na lokalnym sprzęcie.
Balans pomiędzy wielkością modelu a wydajnością
Zawsze istnieje kompromis pomiędzy rozmiarem modelu a jakością odpowiedzi i wydajnością obliczeń. Zasada jest prosta: większe modele generują lepsze odpowiedzi, ale ich działanie jest wolniejsze. Z kolei mniejsze modele są szybsze, ale mogą dostarczać mniej precyzyjne odpowiedzi. W zależności od przypadku użycia, różne priorytety mogą mieć znaczenie – na przykład narzędzia do generowania treści mogą działać w tle, więc ich większa precyzja jest bardziej pożądana. Z kolei asystent konwersacyjny musi działać szybko, jednocześnie udzielając trafnych odpowiedzi.
Najdokładniejsze LLM-y, przeznaczone do pracy w centrach danych, mogą mieć rozmiary sięgające dziesiątek gigabajtów. To sprawia, że tradycyjnie nie mogłyby być w pełni przyspieszane przez GPU na lokalnym sprzęcie. Jednak dzięki technice GPU offloading, model jest podzielony między procesor (CPU) i kartę graficzną (GPU), co pozwala na maksymalne wykorzystanie przyspieszenia GPU, niezależnie od rozmiaru modelu.
Optymalizacja z GPU Offloading i LM Studio
LM Studio to aplikacja umożliwiająca użytkownikom pobieranie i uruchamianie LLM na komputerze stacjonarnym lub laptopie. Oferuje ona intuicyjny interfejs, który pozwala na szeroko zakrojoną personalizację działania modeli. LM Studio jest zoptymalizowane pod kątem współpracy z układami NVIDIA GeForce RTX oraz NVIDIA RTX, co umożliwia korzystanie z przyspieszenia GPU – nawet jeśli model nie mieści się całkowicie w pamięci VRAM.
Dzięki GPU offloading, LM Studio dzieli model na mniejsze fragmenty, zwane „subgrafami”, które są dynamicznie ładowane na GPU i zwalniane, gdy nie są potrzebne. Użytkownicy mogą dostosować liczbę takich warstw przetwarzanych przez GPU, co pozwala na indywidualne dopasowanie wydajności do dostępnych zasobów sprzętowych.
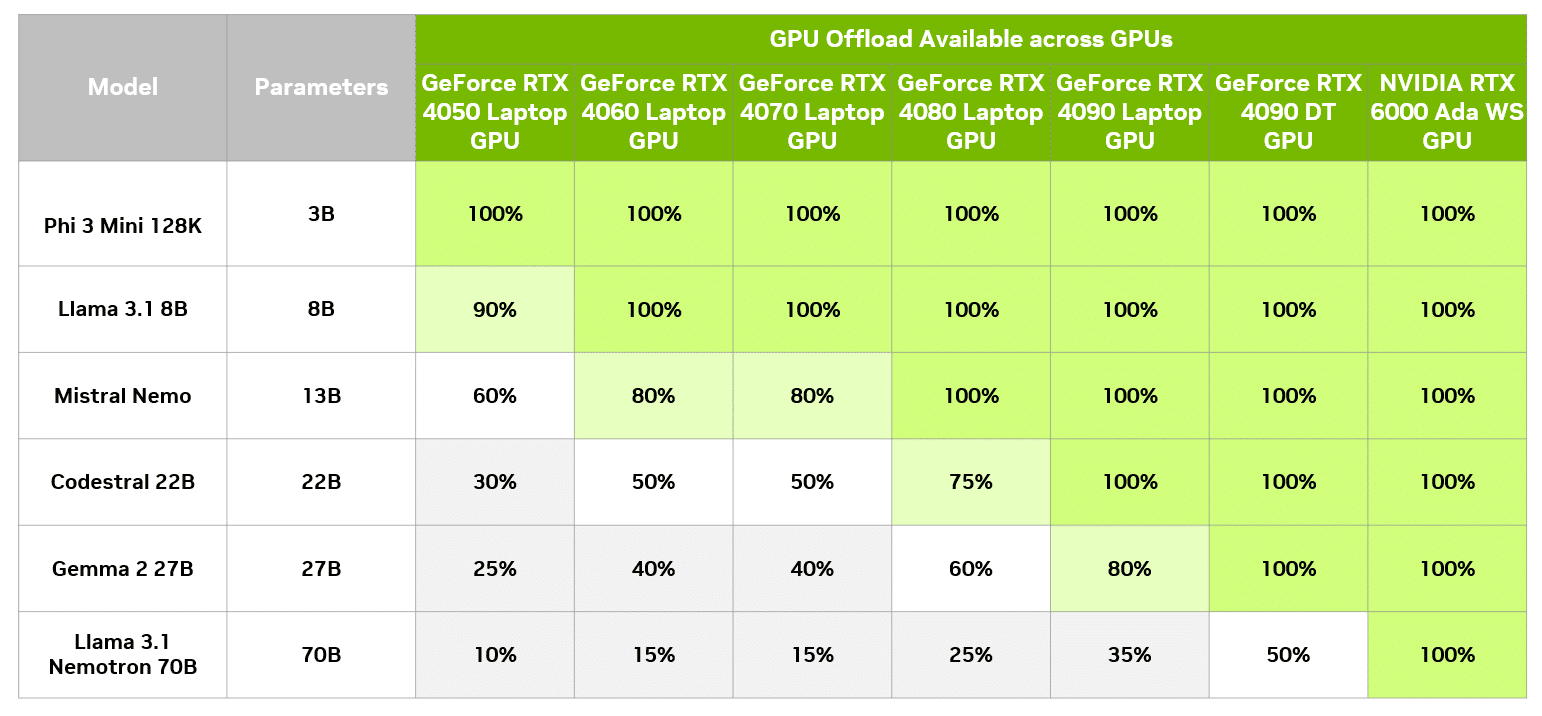
Przykładem może być użycie dużego modelu, takiego jak Gemma 2 27B, który składa się z 27 miliardów parametrów. Przy zastosowaniu techniki kwantyzacji 4-bitowej, rozmiar każdego parametru wynosi pół bajta, co oznacza, że model potrzebuje około 13,5 GB pamięci plus dodatkowe 1-5 GB na obsługę. Na przykład, pełne przyspieszenie tego modelu wymaga 19 GB VRAM, co jest dostępne na karcie GeForce RTX 4090. Jednak dzięki GPU offloading, model może działać na sprzęcie z mniejszą ilością pamięci GPU, a mimo to korzystać z przyspieszenia.
Wydajność GPU Offloading
LM Studio umożliwia użytkownikom monitorowanie wpływu różnych poziomów offloading na wydajność modelu, porównując je z działaniem wyłącznie na procesorze. Na przykład, przy użyciu karty GeForce RTX 4090, wydajność znacząco wzrasta wraz z większym wykorzystaniem GPU. W przypadku modelu Gemma 2 27B, prędkość generowania odpowiedzi wzrasta z zaledwie 2,1 tokenów na sekundę przy obliczeniach na CPU, do znacznie bardziej użytecznych prędkości, gdy GPU jest w większym stopniu zaangażowane w obliczenia.
Nawet użytkownicy posiadający karty graficzne z zaledwie 8 GB pamięci VRAM mogą zauważyć znaczące przyspieszenie w porównaniu do wykonywania obliczeń tylko na procesorze. Oczywiście, mniejsza karta graficzna może również obsłużyć mniejsze modele, które całkowicie zmieszczą się w pamięci GPU, co zapewni pełną akcelerację.
Optymalne wykorzystanie zasobów
Funkcja GPU offloading w LM Studio to potężne narzędzie, które pozwala w pełni wykorzystać potencjał modeli LLM zaprojektowanych do pracy w centrach danych, takich jak Gemma 2 27B, na lokalnych komputerach wyposażonych w układy GPU RTX. Dzięki temu większe i bardziej złożone modele są teraz dostępne dla szerszej grupy użytkowników, korzystających z komputerów z kartami GeForce RTX i NVIDIA RTX.
Pobierz LM Studio, aby samodzielnie wypróbować GPU offloading na większych modelach lub eksperymentować z różnymi LLM przyspieszanymi przez układy RTX na lokalnych komputerach i stacjach roboczych.
Sztuczna inteligencja generatywna zmienia nie tylko branżę gier, ale również wideokonferencje i szeroko rozumiane interaktywne doświadczenia, dając użytkownikom nowe możliwości, które jeszcze niedawno wydawały się odległą przyszłością.

{kind=link}