Jak poprawić jakość agentów LLM dzięki generowaniu kodu i RAG
Źródło obrazu: Favebrush na Shutterstock
Rosnąca popularność dużych modeli językowych (LLM) rewolucjonizuje sposób, w jaki organizacje udostępniają użytkownikom naturalną, konwersacyjną interakcję z różnymi platformami. Połączenie LLM z narzędziami, takimi jak wyszukiwarki, bazy danych czy kalkulatory, otwiera nowe możliwości automatyzacji zadań. Dzięki odpowiednim agentom wykorzystującym LLM, można wybrać najlepsze usługi lub API dla konkretnego problemu i zastosować je z właściwymi ustawieniami.
Tworząc własnego agenta opartego na LLM, PromptAI, umożliwiliśmy użytkownikom dostęp do zaawansowanych danych operacyjnych poprzez intuicyjny interfejs czatowy. Agent ten pomaga eksplorować ogromne ilości danych czasowych, oferując praktyczne wnioski zaczerpnięte z bogatego zbioru wiedzy systemów operacyjnych.
Korzyści wynikające z naszego podejścia
Budując PromptAI, zebraliśmy wiele cennych doświadczeń, którymi chcielibyśmy się podzielić. Kluczowe wnioski obejmują:
- Kod jako interfejs: Zamiast używać JSON jako mostu między LLM a API, zdecydowaliśmy się na generowanie kodu w języku Python. LLM są bardziej precyzyjne w generowaniu kodu niż w tworzeniu złożonych struktur JSON, co poprawia dokładność i minimalizuje błędy.
- Lepsze wybory parametrów dzięki RAG: Zastosowanie generowania wspomaganego wyszukiwaniem (RAG) pomaga ograniczyć liczbę możliwych wartości parametrów, co zwiększa skuteczność i dokładność wyborów LLM.
LLM generuje kod do korzystania z narzędzi
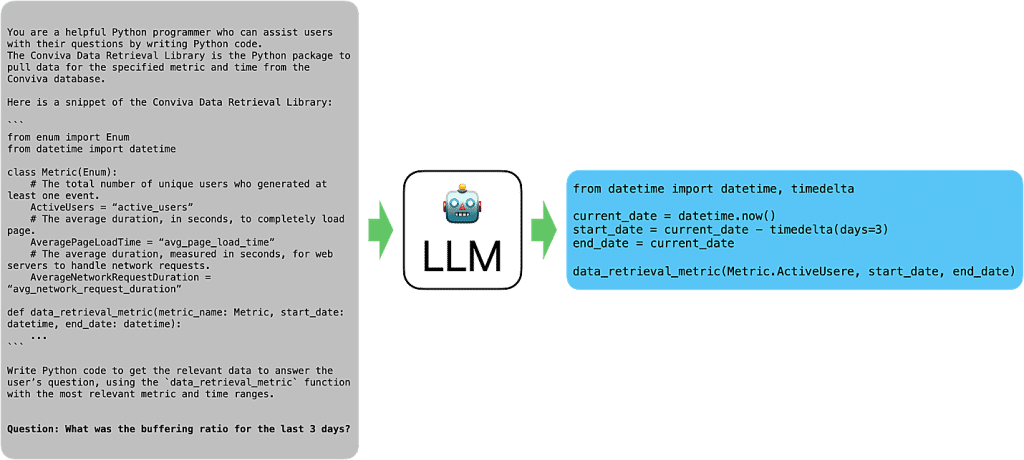
Standardowe interfejsy API zazwyczaj przyjmują dane w formacie JSON. Jednak bezpośrednie generowanie takich struktur przez LLM może prowadzić do błędów, takich jak brakujące klucze, nieprawidłowy typ danych czy błędny format. Przykładowo, aby odpowiedzieć na pytanie „Ilu użytkowników było aktywnych w ciągu ostatnich trzech dni?”, LLM musiałby wygenerować złożony JSON, uwzględniający odpowiednie parametry.
Zamiast tego, zastosowaliśmy podejście polegające na generowaniu kodu. Kod pozwala LLM wyrażać bardziej złożone rozumowanie i wykonywać precyzyjne obliczenia, co nie jest łatwe w bezpośrednim formacie JSON. Dzięki temu, problemy takie jak obliczanie daty sprzed kilku dni, mogą być rozwiązane bardziej dokładnie i efektywnie.
Figura 1: Przykład wejścia i wyjścia LLM przy użyciu kodu Python jako interfejsu
Zaletą tego podejścia jest również wyeliminowanie błędów składniowych, które często pojawiają się przy bezpośrednim generowaniu JSON. LLM są już dobrze wyszkolone w pisaniu kodu, co czyni tę metodę skuteczną, zwłaszcza w połączeniu z wyspecjalizowanymi modelami kodującymi, takimi jak CodeLlama.
RAG jako optymalizacja wyboru parametrów
Wykorzystanie RAG (retrieval-augmented generation) pozwala na dynamiczne dostosowanie wartości parametrów API do konkretnego kontekstu. Dzięki zastosowaniu bazy danych wektorowych, można zawężać pole wyboru LLM, dostarczając tylko te wartości, które są istotne dla danego zapytania użytkownika. Na przykład, jeśli użytkownik pyta o dane dotyczące konkretnego typu urządzenia, RAG może dostarczyć jedynie odpowiednie opcje, eliminując niepotrzebne wartości.
To podejście działa na zasadzie współpracy dwóch procesów myślowych: RAG pełni funkcję szybkiego „myśliciela” (Type 1), dostarczając wstępne wyniki, podczas gdy LLM działa jako bardziej analityczny „myśliciel” (Type 2), wybierając najlepszą opcję. Dzięki tej metodzie zaobserwowaliśmy znaczną poprawę dokładności wyników.
Współpraca wielu agentów
Stworzenie skutecznego agenta LLM wymaga nie tylko integracji API, ale także interpretacji wyników i dostarczania użytkownikowi kontekstowych odpowiedzi. Aby osiągnąć ten cel, połączyliśmy integrację API z RAG oraz wykorzystaliśmy różne modele. Specjalizowane modele, takie jak CodeLlama, zwiększają precyzję w generowaniu kodu, podczas gdy bardziej uniwersalne modele, jak Llama, dostarczają bardziej zrozumiałych odpowiedzi końcowych. To połączenie pozwala maksymalnie wykorzystać moc różnych technologii.
Podsumowanie
Agenci LLM mają ogromny potencjał w automatyzacji zadań i integracji z istniejącymi usługami API. Nasze doświadczenie pokazuje, że wykorzystanie kodu zamiast JSON jako interfejsu poprawia dokładność i efektywność. Dodatkowo, zastosowanie RAG umożliwia dynamiczne dostosowanie parametrów, co jeszcze bardziej usprawnia działanie systemu. Łącząc te techniki, udało nam się stworzyć bardziej precyzyjnego i funkcjonalnego agenta, który w intuicyjny sposób wspiera interakcję użytkowników z danymi.
{kind=link}